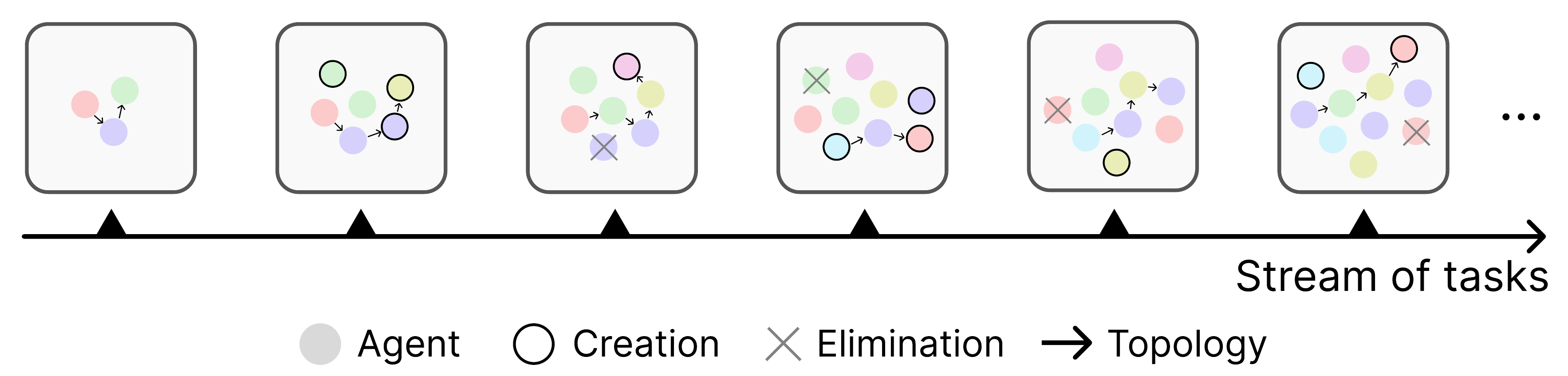
How can agents self-orchestrate without central control? We study an agent economy inspired by Hayekian markets: agents bid for the right to act, exchange payments, and gain wealth from rewards. These signals create decentralized credit assignment and planning. Effective agents persist and mutate; ineffective ones go bankrupt and are replaced.
Starting from weak agents, the economy discovers multi-step reasoning strategies and outperforms stronger monolithic baselines across math, finance, science, accelerator design, and distributed-system optimization. We also connect local incentives to long-term collective performance.
Design the incentives, not the coordination.
We replace central orchestration with a price system. Each agent has a wake-up condition, fixed bid, and wealth balance. Auctions select actors, payments move credit backward, and rent/bankruptcy prune weak agents. Specialization and coordination emerge from these simple rules.
An economy of language agents
We model language agents as an economy. Each agent acts locally from its trigger and policy, while global coordination emerges from prices. The system has two loops: planning, which selects actions and assigns credit within an episode, and adaptation, which evolves the population across episodes.
3.1Problem setup
We model the task as a partially observed Markov decision process ℰ = (𝒮, 𝒜, P, r, γ, μ0), with state space 𝒮, action space 𝒜, transition kernel P(s' | s, a), reward r, discount γ, and initial-state distribution μ0. At step t, the system observes ot ∈ 𝒪.
All agents share a frozen LLM backbone; diversity comes from prompts. Each agent is a tuple
where φa : 𝒪 → {0, 1} is a triggering predicate for eligibility, πa : 𝒪 → Δ(𝒜) is its policy, ba ∈ ℝ≥0 is its bid, and Wa ∈ ℝ is its wealth. The trigger and policy use agent-specific prompts pa = (patrig, paact). At episode e, the active population is 𝒫e. This generalizes Baum's Hayek machine from hand-written rules to prompted LLM agents.
3.2Planning with auctions and transactions
At each step, agents compete for control. Given observation ot, each agent checks its trigger. The eligible set is
If Et = ∅, no agent acts. Otherwise, the highest-bidding eligible agent wins:
with random tie-breaking. Control goes to the highest bidder in the current context, without a central policy.

The winner at★ acts, producing ot+1 and reward rt. Let at-1★ be the previous winner. We then apply a bucket-brigade transfer rule:
The winner pays its bid to the previous actor and receives any reward rt. The first payment in an episode goes to the house.
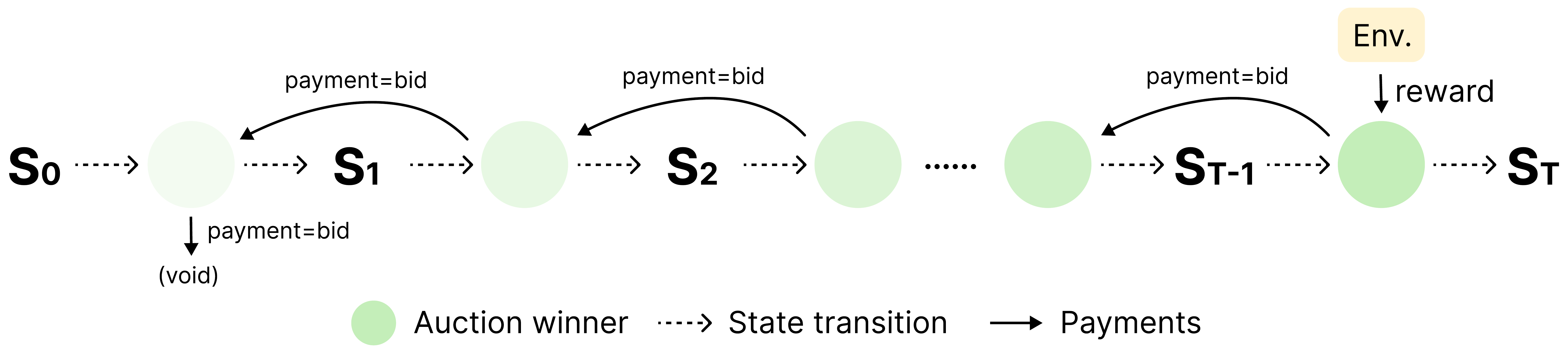
This creates decentralized credit assignment. Agents profit by earning reward or by creating states that downstream agents value. Productive actions accumulate wealth; unproductive ones lose it.
3.3Adaptation with exploration and exploitation
Across episodes, economic selection evolves the population. A prompt generator 𝒢 proposes new agents by mutating successful prompts or amending failed ones. New agents start with wealth W0 ≥ 0; existing agents may pay rent ρ ≥ 0.
Exploitation.
Useful agents accumulate wealth, persist, and periodically spawn mutations. This reuses strong behaviors, refines them, and encourages specialization. Mutations preserve useful triggers or policies while adding small variations.
Exploration.
Weak or inactive agents lose wealth. Once bankrupt, they are removed and replaced by random or complementary variants. This turnover learns from failures, explores new behaviors, and reduces premature convergence.
Between episodes, the population update has three stages:
- Rent: each agent pays ρ, so Wa ← Wa − ρ;
- Removal: agents with Wa < 0 are deleted;
- Injection: new agents are added according to exploitation and exploration until the population satisfies the prescribed maximum-size constraints.
Bids are assigned at birth and then frozen. For a new agent a′, let t be its first eligible step, and let Ct = { a ∈ 𝒫e ∖ {a′} : φa(ot) = 1 } be competing eligible agents. Its bid follows the novice rule:
with max ∅ := 0 and 𝒟ε a small positive perturbation. The rule ensures a new eligible agent is tested once before market selection decides whether it survives.
Exploitation preserves useful behaviors; exploration adds novelty. Evolution is driven only by wealth gains and losses, with no central supervision or global labels.
3.4Training and evaluation
During optimization, agents bid for control, act, transfer wealth, and receive environmental rewards. These signals drive adaptation: bankrupt agents are removed, profitable ones persist, successful prompts mutate, and the population is replenished.
During evaluation, the population and bids are frozen. Payments, rewards, rent, births, and mutations are disabled, and each test task runs on a thread-local snapshot. Evaluation therefore measures the learned policy without further wealth dynamics.
Experiments
5.1Setup
Partial vs. complete agents.
A partial agent has limited tools, actions, context, or output budget. A complete agent has the full task interface. This tests whether economic organization can rival capability concentrated in one agent.
Baselines.
We compare against complete-agent baselines (ReAct, GEA, OpenEvolve), a partial-agent baseline (Multi-Agent Debate), and DOSA for accelerator design.
5.2Can economics turn weak individuals into stronger systems?
Across five domains, economic coordination turns partial agents into stronger systems. On MATH, EoM improves Llama-3.1-8B from 15.9% → 57.0% and Gemma-2-9B from 4.2% → 45.1%, beating complete-agent baselines. On accelerator design, EoM lowers average EDP to 39.3, versus 43.1 for complete ReAct and 80.2 for DOSA.
Task. Finance-Agent-Bench with four tools; each partial agent gets one.
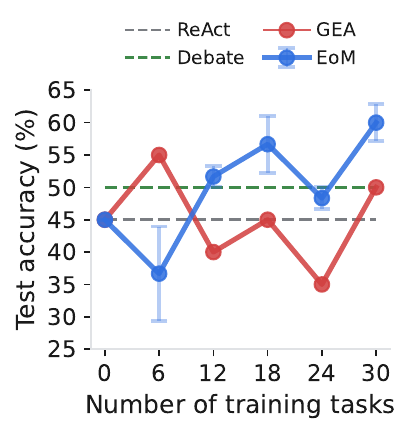
Task. FrontierScience-Research with literature, planner, executor, and verifier roles.
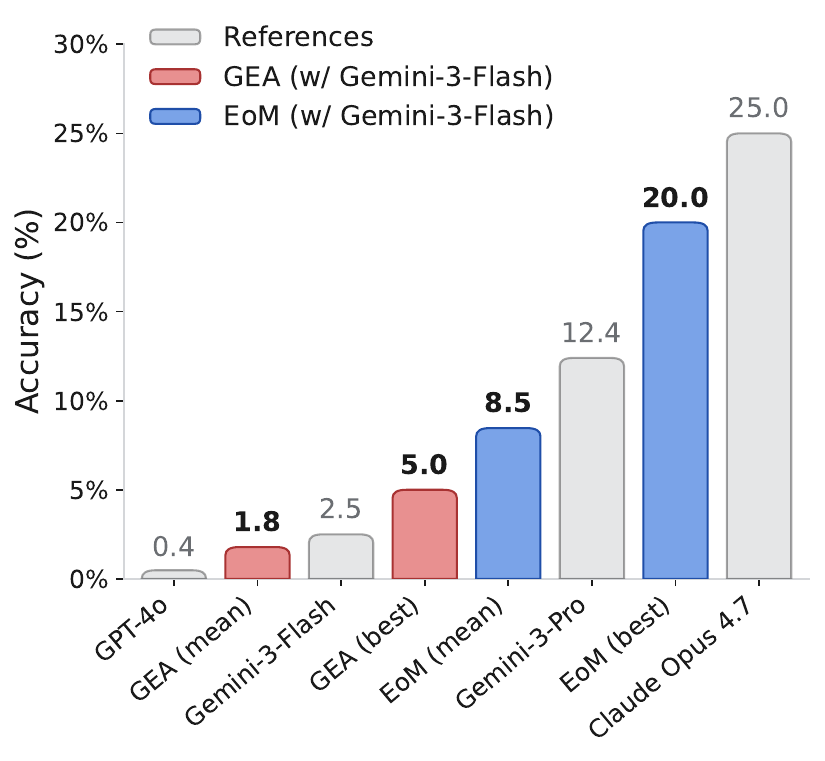
Task. Cloudcast from ADRS: iteratively improve a program to reduce data-transfer cost.
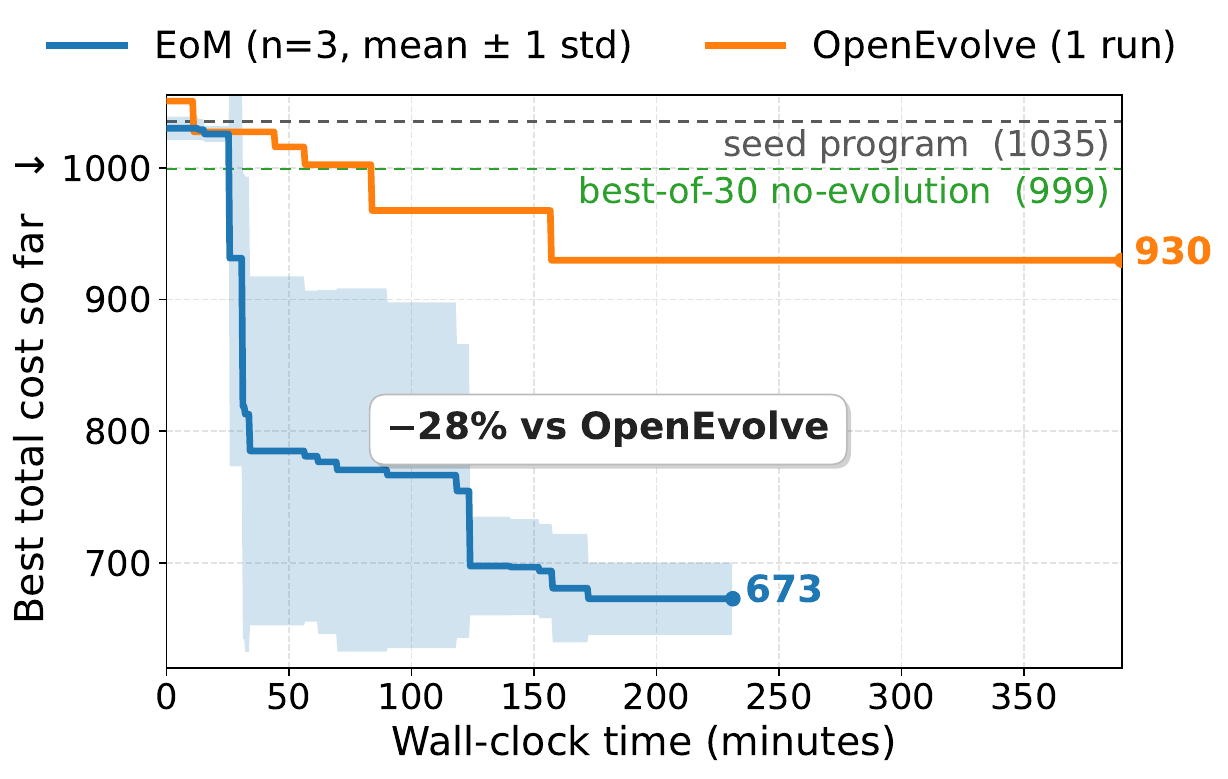
The gain is not just “many agents.” Economic interactions let limited agents match or surpass stronger complete agents.
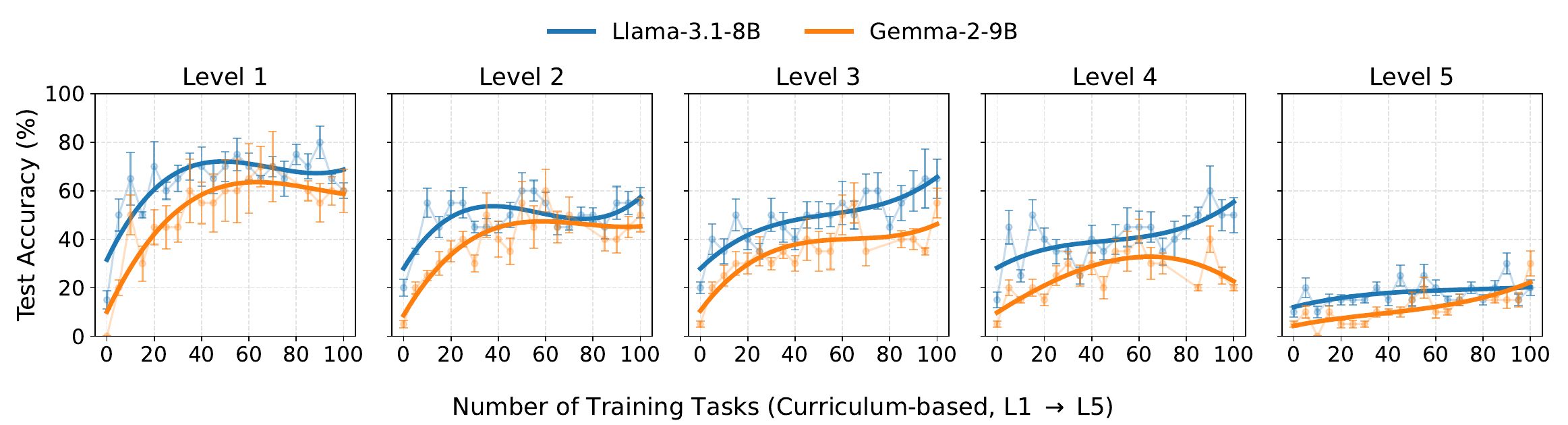
Task. MATH on an easy-to-hard stream, with planner/executor/verifier agents capped at ~128 output tokens.
| Backbone | Partial agents | Complete agent | |
|---|---|---|---|
| Initial | After training | ||
| Llama-3.1-8B | 15.9 (1.37) | 57.0 (3.36) | 51.9* |
| Gemma-2-9B | 4.2 (0.52) | 45.1 (4.12) | 44.3* |
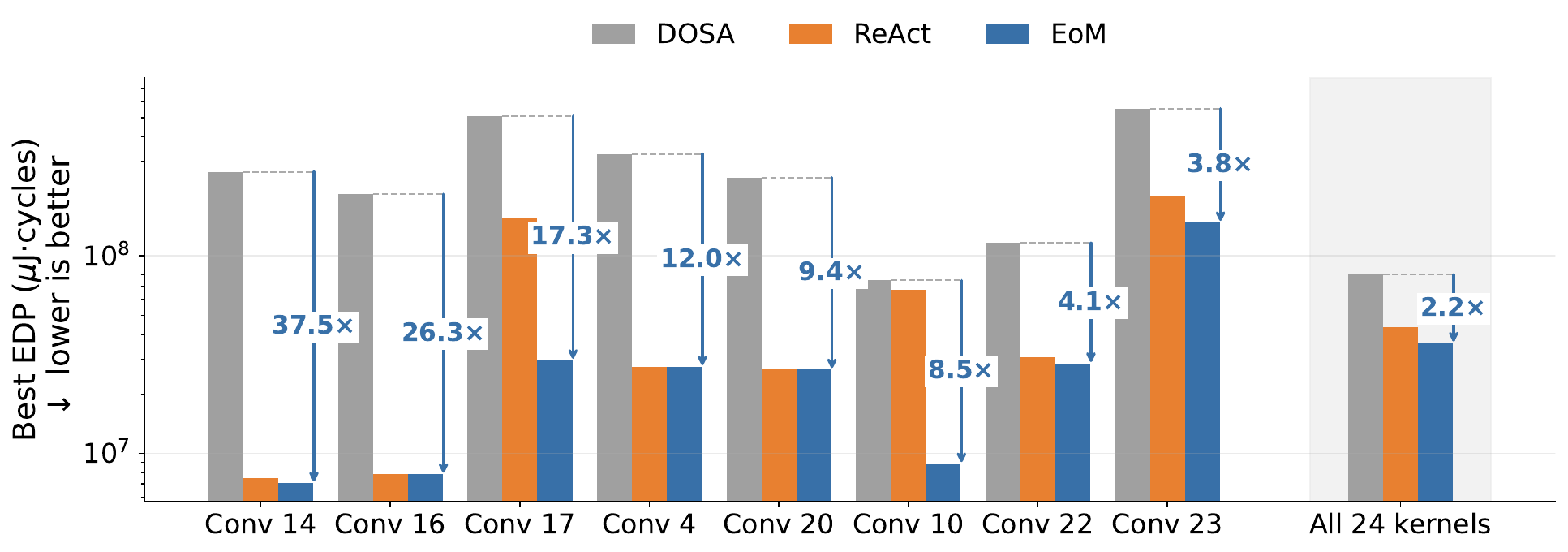
Task. Gemmini mapping search over 24 ResNet-50 kernels, minimizing EDP with Historian/Planner/Executor roles.
| Method | Avg. EDP ↓ |
|---|---|
| DOSA | 80.2 |
| Complete agent (Gemma-4-31B-it) | 43.1 |
| EoM (Gemma-4-31B-it) | 39.3 |
Table 1. Performance. Left: MATH accuracy (* official numbers). Right: accelerator-design average EDP (lower is better). EoM outperforms the corresponding baselines.
5.3Beyond multiple agents: the role of economic ingredients
The gains depend on economics, not just multiplicity: control allocation, value transfer, selection, and propagation all matter. Weakening them reduces performance.
On MATH, the original setting is strongest among constrained variants (43.9 mean / 57.0 best). On Finance-Agent-Bench, removing exploration, exploitation, or auctions all hurts. Cloudcast reinforces the point: EoM reaches 673 best cost, while best-of-N sampling reaches 999.
Table 2. Ablations. Economic parameters and component removals both affect performance; the full/original system is strongest overall.
5.4How does the economy improve performance?
What changes inside the society as performance improves?
EoM improves by reshaping both agents and population structure. On Finance-Agent-Bench, performance dips during exploration, then rises from 45.0 to 60.0 as control shifts toward stronger specialists.
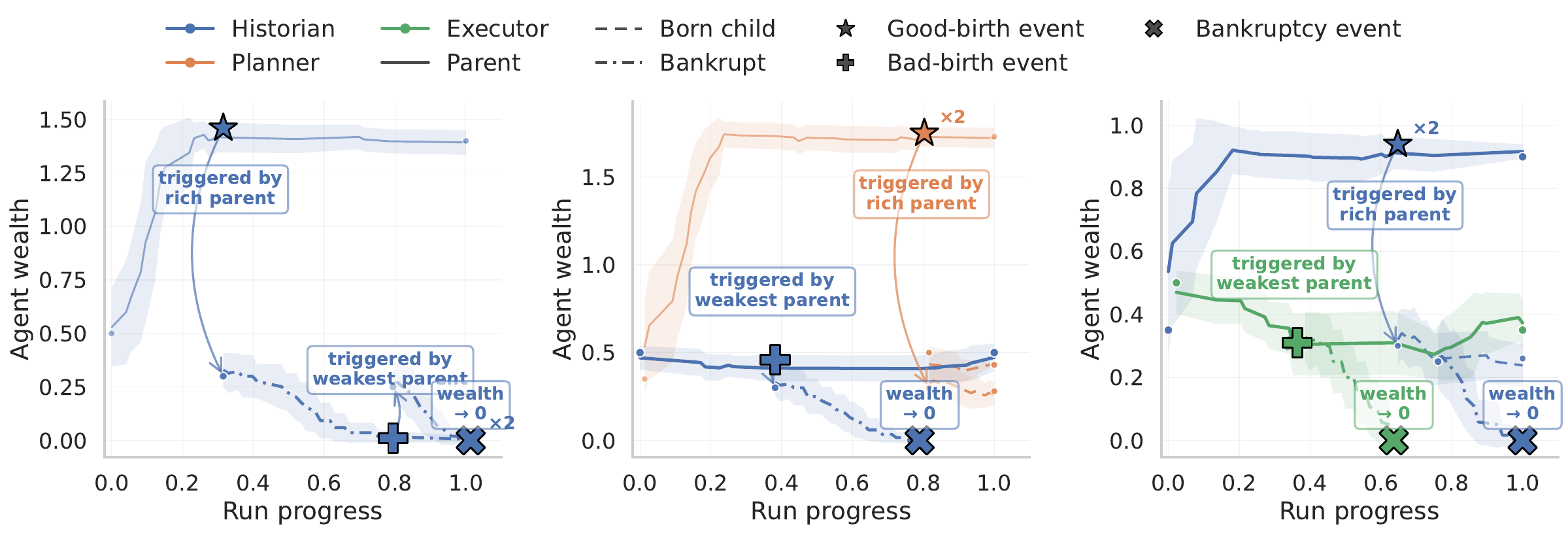
Does the society learn reusable structure?
EoM achieves a 2.2× geometric-mean EDP gain over DOSA across 24 ResNet-50 kernels, with much larger gains on the hardest 1×1 bottlenecks. Without being given the output-stationary motif, the population repeatedly rediscovers it through EDP rewards.
5.5Robustness and generalization
Do learned behaviors transfer from easier tasks to harder ones?
On MATH, easy-to-hard training improves every difficulty band, including harder levels not seen early. Both backbones lift Level 5 from ~10% to ~20%, suggesting simple routines transfer to harder problems.
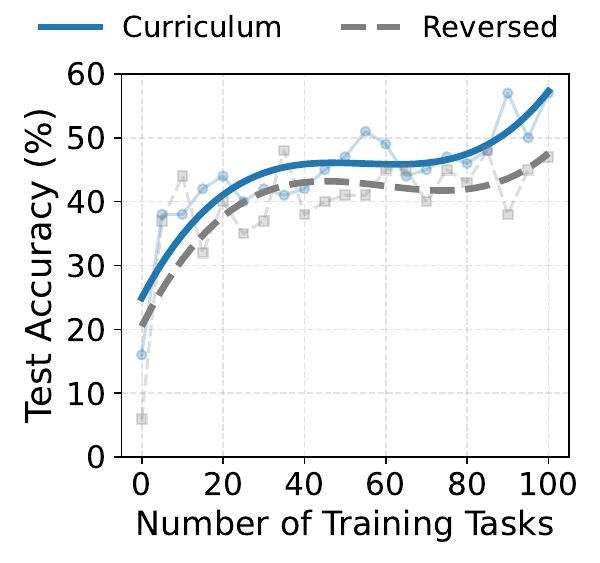
How sensitive is the society to curriculum order?
Both schedules improve early, but easy-to-hard stays ahead and finishes higher: ~57% versus ~47%. Partial specialists benefit from learning reusable routines before facing the hardest problems.
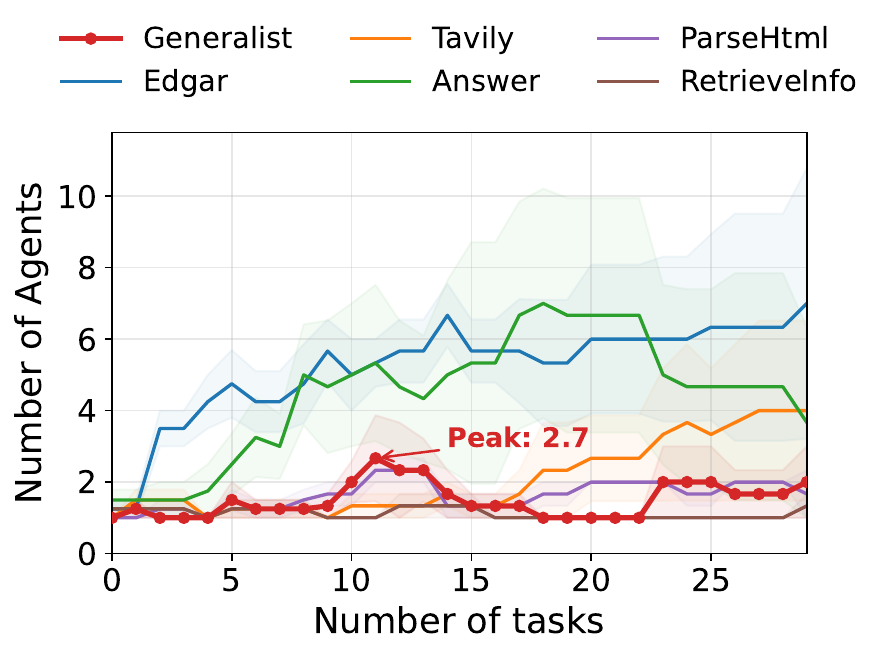
Can a complete generalist monopolize the economy?
Adding an all-tool generalist does not collapse the society. It briefly expands, then shrinks back to one agent while specialists keep growing. The economy rewards local precision over broad but diluted capability.
Economic dynamics shape both agent policies and social structure. Coordination emerges from aligned local incentives.
From engineering coordination to designing incentives
Simple economic interactions among prompted LLM agents recover specialization, credit assignment, and cross-task transfer across five domains. Rather than centrally engineered pipelines, EoM points toward evolving agent societies shaped by their economies.
Limitation: adaptation is prompt-space only; parameter-space, hybrid, multimodal, and embodied extensions remain future work.